
China’s AI evolution is surging once again! Months ago, we were still in a competition where DeepSeekAI and Qwen models were built to rival top-tier models like GPT-4o, Claude 3.5 Sonnet and DeepSeek V3.

Now, it seems we’re in the midst of a Chinese digital revolution. Today, a new wave of debate has seized global attention with the innovative AI-generated video tool known as OmniHuman. With ByteDance’s OmniHuman-1 redefining AI video generation and DeepSeek’s breakthroughs in cost-efficient models, are you curious to know some interesting facts about OmniHuman and discover how the Chinese are setting new global standards in artificial intelligence? Follow me as we unravel this game-changing AI model.
ByteDance, the parent company of TikTok, is the originator of OmniHuman-1, a groundbreaking AI tool that generates lifelike human videos from minimal input. This technological innovation puts China on the global map and positions the country as a leading contender in the global AI race. In this piece, I will explore its benefits, challenges and limitations. I will also share samples generated with OmniHuman-1 and simple steps to navigate it for free.
Table of contents
OmniHuman: The New AI Model That Generates Realistic Video From a Photo
Limitations of Existing Models
OmniHuman-1 Limitations & Drawbacks
Future Developments & Applications
What is OmniHuman-1?
OmniHuman-1 excels at creating realistic human videos that stand, gesture, and express emotions in sync with speech or music. What’s even more impressive is that it simplifies the entire process, eliminating complex setups and limitations of existing methods. Whether a user wants to create a portrait, half-body shot, or full-body image, OmniHuman-1 handles it all with lifelike human motion, natural gestures, and stunning attention to detail.

At its core, OmniHuman-1 is a multimodality-conditioned AI-driven human animation which integrates different types of inputs, including images and audio clips, to generate highly realistic human videos, making a digital human stand up, gesture with arms and hands, and express emotions in sync with speech or music. It is also interesting that OmniHuman-1 can work with a single image. No more worrying about complex setups or the limitations of existing models—OmniHuman simplifies it all and does it better than anything you think you’ve seen so far.
Read Also: How DeepSeek, the Chinese AI, is Disrupting Global Tech: 5 Things You Should Know
Limitations of Existing Models
Research has shown that current AI-driven human animation models often depend on small datasets and are tailored to specific scenarios, leading to subpar quality in the ai generated lifelike videos. Many existing methods struggle to generalize across diverse contexts, resulting in animations that lack realism and fluidity. These omnihuman models often fail to accurately capture body movement, facial expressions, and human-object interactions, making it difficult to create realistic animation.
Moreover, the reliance on single input modalities—where the AI model only receives information from one source rather than combining multiple sources like text and images—limits their capacity to capture the complexities of human motion. As the demand for high-quality AI generated content grows, there is an increasing need for frameworks that integrate multiple data sources to enhance the quality of realistic human videos.
The OmniHuman-1 Solution

Source: OmniHuman-1 Research Paper
Multi-Conditioning Signals
OmniHuman-1 effectively integrates multiple inputs, including text, audio, and pose data, ensuring highly realistic motion. This comprehensive approach allows the model to produce realistic and contextually rich animations, setting it apart from existing Ai generated media.
Omni-Conditions Design
OmniHuman-1 employs an omni conditions training strategy that integrates various driving conditions (text, audio, and pose) while preserving the subject’s identity and background details from reference images. This technique enables the AI tool to generate portrait contents that maintain consistency and realism.
Unique Training Strategy
ByteDance researchers developed a unique training strategy that enhances data science utilization by leveraging stronger conditioned tasks (such as precise pose data) alongside weaker conditions (like audio cues). This method ensures high-quality human video data even from imperfect reference images or audio inputs.
OmniHuman-1 Limitations & Drawbacks
Despite its impressive features and unlimited capabilities, let me briefly share with you some of the drawbacks and the challenges it raises for new users:
OmniHuman-1, like many advanced AI models, is a double-edged sword. Though It offers incredible creative possibilities, but also comes with technical and ethical limitations that must be taken into consideration, so let us compare and contrast it with other AI video generators:
OmniHuman-1 vs. Sora vs. Veo 2
OmniHuman-1 joins a competitive field of AI video generators. Two of the most prominent rivals are OpenAI’s Sora and Google’s Veo 2. While all three have different focuses and strengths, OmniHuman-1 excels in creating AI-generated videos with hyper-realistic human motion.
| Model | OmniHuman-1 (ByteDance) | Sora (OpenAI) | Veo 2 (Google) |
|---|---|---|---|
| Best for | Animating real people with hyper-realistic human motion. | Generating diverse videos from text prompts. | High-resolution cinematic-quality video generation. |
| Primary input | Single image + audio (optional video/pose data). | Text prompt (optionally guided by images/videos). | Text prompt (optionally guided by images). |
| Strengths | Unmatched realism in human video generation, full-body animation, and perfect lip-sync. | Creative scene generation from text, flexible input options. | High-resolution output (up to 4K), strong physics, and realism. |
| Weakness | Not publicly available yet, high computational requirements. | Struggles with detailed human expressions in some cases. | Not specialized for talking-head videos, more general-purpose. |
Source: techopedia.com
The Challenge to U.S. AI Dominance
According to research, ByteDance, the Chinese company behind TikTok, has unveiled OmniHuman-1, one of the most advanced generative AI models for creating realistic human videos. This development highlights the increasing competition between Chinese and U.S. companies in the field of artificial intelligence.
While U.S. companies have largely led in foundational AI models like GPT-4 and DALL-E, Chinese tech firms have been rapidly catching up and, in some cases, breaking new ground. The release of OmniHuman-1 follows other impressive Chinese-developed models like DeepSeek R1, signalling China’s intent to compete at the highest level in AI. ByteDance’s OmniHuman-1 excels in the specific niche of realistic human video generation, potentially surpassing existing methods in accuracy and personalisation.
For ByteDance, this is a strategic move to solidify TikTok’s platform with unique content creation tools that Western rivals may not immediately match. By offering advanced features like the ability to generate lifelike videos from a single image and motion signals, ByteDance aims to enhance user engagement and attract more creators to its platform. However, experts have expressed concerns that the technology, if made available for public use, could lead to new abuses and magnify national security concerns.
Read Also: What are the 7 Best GRC Courses for 2025
Future Developments & Applications
OmniHuman-1’s cutting-edge technology is expected to influence future AI avatars, virtual characters, and realistic animation projects. The rise of AI-generated media also raises concerns about misinformation and ethical considerations.
Videos Generated by OmniHuman-1
OmniHuman-1 generates AI-driven human animation using a single photo and motion signals such as audio. It supports various visual and audio styles, producing videos at any aspect ratio and body proportion (half-body, portrait, or full-body). The model captures subtle facial expressions, upper body movements, and challenging body poses with stunning accuracy, achieving natural human appearances and smooth transitions between movements.
OmniHuman-1 is a major advancement in deepfake technology, capable of producing extremely realistic human videos with unmatched precision. Sample videos demonstrate the model’s ability to handle different aspect ratios and body proportions, making it suitable for various media formats.
Examples of OmniHuman-1 in Action
X/Twitter user AshutoshShrivastava shared a set of samples generated with OmniHuman-1:
1. Singing
OmniHuman-1 captures the nuances of music, translating them into realistic body movement and facial expressions.
For instance:
Gestures match the rhythm and style of the song.
Facial expressions align with the mood of the music.
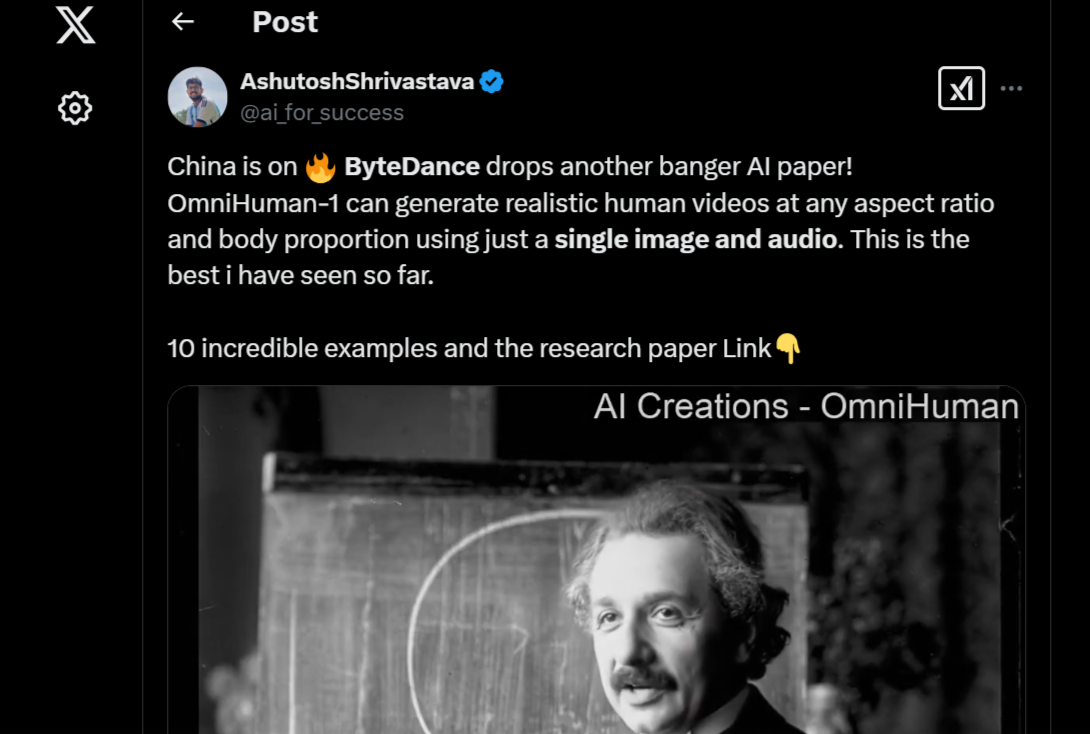
2. Talking
This AI model generates highly realistic talking avatars with precise lip-sync and human video data integration. In a video sample released in the research paper, OmniHuman transformed a still image of Albert Einstein’s portrait into a video of the theoretical physicist delivering a lecture.
Applications include:
Entertainment.
Virtual influencers.
Educational content.
OmniHuman supports videos in various aspect ratios, making it versatile for different types of content.
3. Virtual Influencers
OmniHuman-1 is ideal for creating virtual influencers and AI avatars, revolutionizing the social media landscape.
4. Cartoons and Anime
OmniHuman-1 can animate artificial objects, cartoons, and animals, expanding its potential applications beyond human videos.
For example, It can animate:
Cartoons.
Animals.
Artificial objects.
This adaptability makes it suitable for creative applications, such as animated movies or interactive gaming.
4. Portrait and Half-Body Images
OmniHuman delivers lifelike results even in close-up scenarios. Whether it’s a subtle smile or a dramatic gesture, the model captures it all with stunning realism.
5. Video Inputs
OmniHuman can also mimic specific actions from reference videos. For example:
Use a video of someone dancing as the motion signal, and OmniHuman generates a video of your chosen person performing the same dance. Combine audio and video signals to animate specific body parts, creating a talking avatar that mimics both speech and gestures.
Pros and Cons
Pros:
- Multi-modal AI tool for generating lifelike human videos
- Works with limited data while producing highly realistic motion
- Captures detailed body movement and facial expressions
- Suitable for AI-generated content in entertainment, education, and social media
Cons:
- Requires significant computational power
- Limited availability as it is not yet publicly accessible
- Ethical concerns around deepfake technology and misinformation
How to Use OmniHuman-1
Step 1: Input
Start with a single image, a single photo, or a reference video.
Step 2: Processing
The AI model processes motion data using multimodal conditioning to generate realistic animation.
Step 3: Output
The final AI generated video includes precise body proportion details, smooth human motion, and lifelike animations.
FAQs
Who owns OmniHuman-1?
OmniHuman-1 is developed by ByteDance, the company behind TikTok. Reuters reported last month. The company had already launched some AI-powered tools in China in 2024, but now it has arrived with its most ambitious AI product to date.
Is OmniHuman-1 better than Sora or Veo 2?
OmniHuman-1 ai model is best for animating real people with hyper-realistic human video data, while Sora and Veo 2 specialize in AI-generated media and cinematic scenes.
What is the best AI video generator?
The best AI video generator depends on your needs. OmniHuman-1 is ideal for realistic video generation, while Sora and Veo 2 cater to broader AI-generated video applications.
Babatunde Qodri is a tech blogger, cybersecurity analyst, and SEO specialist who writes about flexible working, freelancing, side hustles, and skill development for millennials and Gen Z. He can be reached via: babatundelaitan@gmail.com X – @_BabatundeQodri